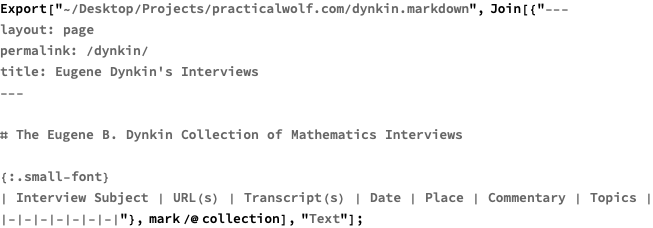
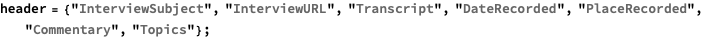Recovering Dynkin’s interviews
Mathematician Eugene B. Dynkin (1924-2014) conducted over 200 interviews with various mathematicians, and Cornell University Library has digitized this collection. However, that site is currently is broken as it required Flash to play audio and video files, and most of the pages throw PHP errors. In this blog post, we scrap audio and video links to underlying files, along with the metadata, to make this information available again until Cornell fixes its archive.
Extracting interview video/audio links and metadata
The interviews TOC has links to all individual interview pages /node/xxx so that we can get all 200+ of them:


Looking at the individual page’s XML soup, we can see that it has several div pairs with classes field-label and field-items.



In Interview URL the flash player information is URL encoded in an XML element param with name=flashvars, so we need to extract ‘url’: ‘xxx’ parts.
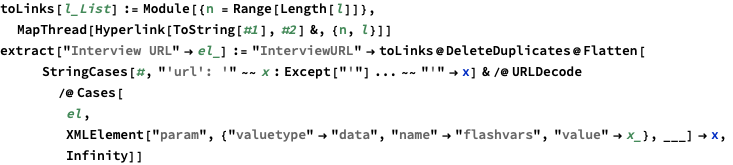
In Translation or Transcription, there are typically a few hyperlinks, so we need to extract them.

For all the other fields, we extract all the strings and concatenate them together.


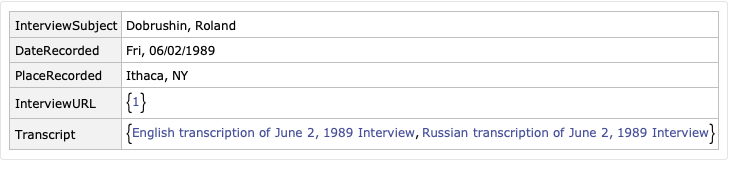
Parsing the whole collection
Since we might want to revise our extraction logic as we encounter more edge cases, it would make sense to download and parse every URL just once and cache the resulting XML objects.


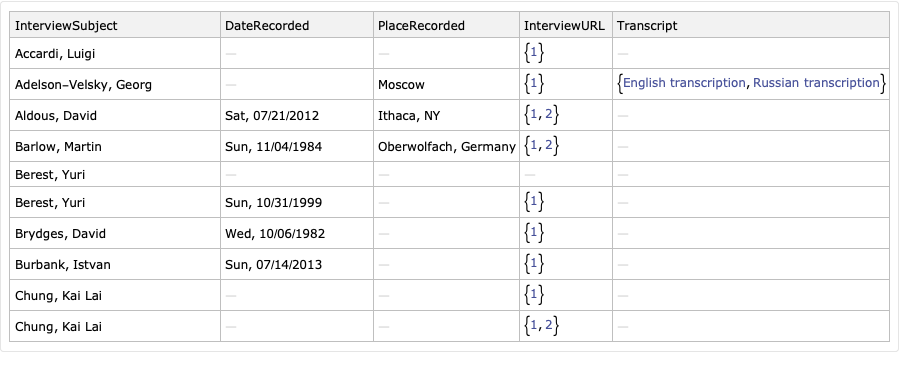
Here is a full list of fields in the interview metadata, although many of these are missing.

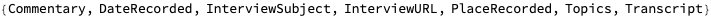
The last touch will be to save the above collection in some sensible format. The easiest would probably be a static HTML file with direct links to Cornell collection. The easiest would be to generate a markdown file with a table that can be converted to HTML by Jekyll that runs this site. The final table is available here.